
大型语言模型 (LLMs) 是什么,它们如何工作?
大型语言模型(LLMs)是推动生成式人工智能聊天机器人迅猛崛起的核心技术。像ChatGPT、Google Bard和Bing Chat这样的工具都依赖于LLMs来生成类似人类回应的答案。
那么,LLMs究竟是什么,它们又是如何工作的呢?下面我们将揭开LLMs的神秘面纱。
什么是大型语言模型?
简单来说,LLMs是一个庞大的文本数据数据库,可以用于引用和生成类似人类回应的文本。这些文本包括来自各种来源的文字,可以达到数十亿字。
通常使用的文本数据来源有:
- 文学:LLMs通常包含大量的当代和古典文学。这包括书籍、诗歌和戏剧。
- 在线内容:LLMs通常包含大量的在线内容,包括博客、网页内容、论坛问答和其他在线文本。
- 新闻和时事:一些LLMs可以获取当前新闻话题,但并非所有LLMs都可以。例如,GPT-3.5在这方面有限制。
- 社交媒体:社交媒体是自然语言的重要资源。LLMs使用来自Facebook、Twitter、Instagram等主要平台的文本。
当然,拥有庞大的文本数据库只是一方面,LLMs还需要经过训练才能理解这些文本并生成类似人类的回应。下面我们将介绍它是如何做到这一点的。
LLMs是如何工作的?
LLMs如何利用这些数据库来生成回应呢?第一步是使用一种称为深度学习的过程分析数据。
深度学习用于识别人类语言的模式和细微差别。这包括理解语法和句法。但是,更重要的是,它还包括上下文。理解上下文是LLMs的一个关键部分。
让我们以一个例子来说明LLMs如何使用上下文。
下面的图片中的提示提到在晚上看到了一只蝙蝠。从这个提示,ChatGPT理解我们在谈论一个动物,而不是一个棒球球棒。当然,其他聊天机器人如Bing Chat或Google Bard可能会给出完全不同的回答。
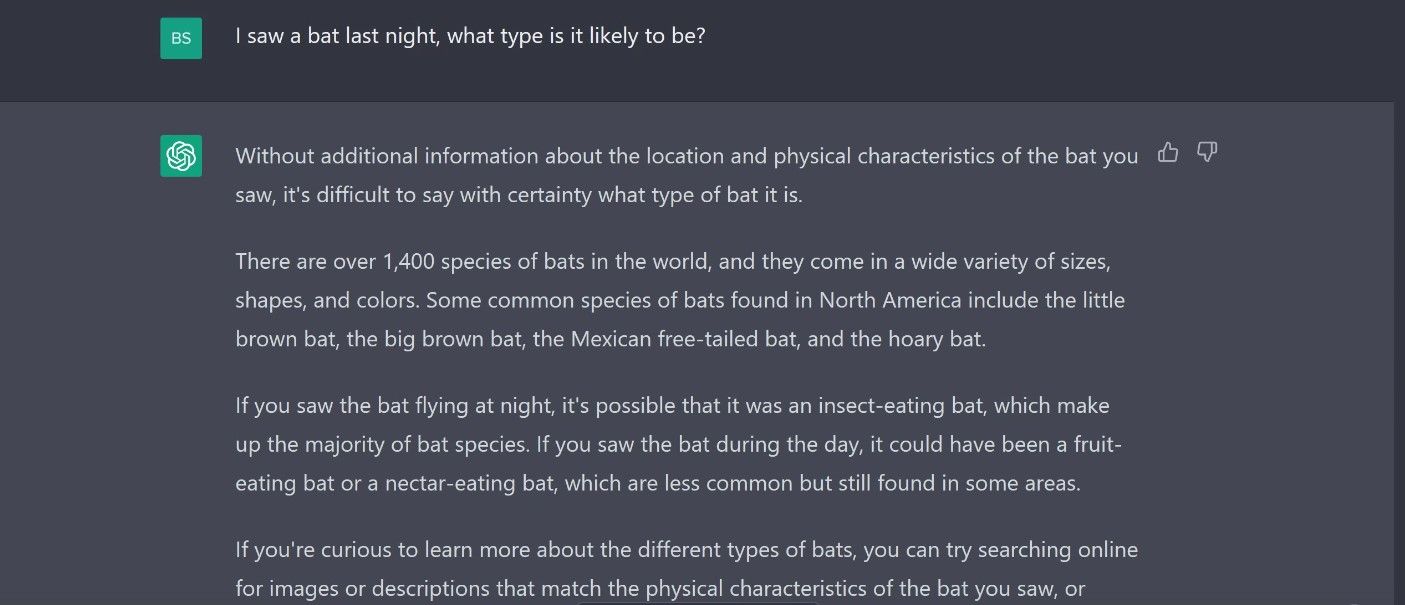
然而,LLMs并非完美无缺的,正如这个例子所示,有时你需要提供额外的信息才能得到所需的回答。
例如,在下面的示例中,我们故意提出了一个稍微复杂一点的问题,以展示上下文很容易丢失的情况。但是人类也会误解问题的上下文,只需要一个额外的提示就可以矫正回答。
为了生成这些回答,LLMs使用一种称为自然语言生成(NLG)的技术。它通过分析输入并利用其数据库学习到的模式生成与上下文相关且合理的回答。
但是LLMs的工作不仅止于此。它们还可以根据输入的情绪色彩定制回答。当与上下文理解相结合时,这两个方面是LLMs生成类似人类回应的主要驱动因素。
总结一下,LLMs利用庞大的文本数据库以及深度学习和NLG技术生成与你的提示类似人类的回应。但是这种技术也有其局限性。
LLMs的局限性是什么?
LLMs代表了令人印象深刻的技术成就。但是,这项技术还远未达到完美,并且仍然存在许多限制。以下是一些比较显著的限制:
- 上下文理解:我们提到LLMs将上下文纳入答案中。然而,它们并非总能正确理解上下文,有时无法理解上下文,导致不当或完全错误的回答。
- 偏见:训练数据中存在的任何偏见通常也会在回答中体现出来。这包括对性别、种族、地理位置和文化的偏见。
- 常识:常识很难量化,但人类通过观察周围的世界从小就学会了常识。LLMs并没有这种内在的经验可以依靠。它们只能理解通过训练数据提供给它们的内容,这并不能使它们真正理解它所存在的世界。
- LLM只有其训练数据那样好:准确性无法保证。计算机上古老的格言“垃圾进、垃圾出”完美概括了这个局限性。LLMs只能依靠其训练数据的质量和数量来决定其好坏。
更进一步,道德问题也可以被认为是LLMs的局限性,但是这个问题超出了本文的范围。
3个知名LLMs实例
人工智能的持续发展现在在很大程度上依赖于LLMs。尽管它们不算是新技术,但它们已经达到了一个关键的发展阶段,并且现在有许多模型可供选择。
下面是一些广泛使用的LLMs:
- GPT(Generative Pre-trained Transformer):GPT可能是最知名的LLM。本文中的示例使用了GPT-3.5来支持ChatGPT平台,而最新版本GPT-4则可通过ChatGPT Plus订阅获得。微软还在其Bing Chat平台中使用了最新版本。
- LaMDA:这是Google Bard最初使用的LLM。Bard最初推出时使用的是LLM的“轻量级”版本,后来又推出了更强大的PaLM版本。
- BERT(Bi-directional Encoder Representation from Transformers):BERT代表双向编码器表示来自变压器的方法。与GPT等其他LLMs不同,BERT具有双向特性。
还有许多其他的LLMs正在开发中,并且从主要LLMs中也常常会出现分支。随着技术的发展,LLMs将在复杂性、准确性和相关性方面不断发展。那么LLMs的未来会如何呢?
LLMs的未来
LLMs无疑将塑造我们未来与技术互动的方式。ChatGPT和Bing Chat等模型的快速普及就是这一事实的证明。在短期内,人工智能不太可能取代人们在工作中的角色。但是关于这些技术在我们生活中发挥多大作用仍存在不确定性。
伦理问题可能会对我们如何将这些工具纳入社会发挥影响力提出意见。然而,暂且不谈这个问题,LLMs未来的发展可能包括:
- 提高效率:LLMs具有数亿参数,对计算资源要求极高。随着硬件和算法的改进,它们可能变得更加节能高效,也会加快响应时间。
- 改进上下文理解:LLMs是自我训练的,使用越多并得到反馈,它们就会越好。重要的是,这不需要进行进一步的重大工程。随着技术进步,语言能力和上下文意识将得到改进。
- 训练特定任务:那些作为LLMs公众形象的万事通工具往往容易出错。但是随着它们的发展和用户针对特定需求进行训练,LLMs可以在医学、法律、金融和教育等领域发挥重要作用。
- 更大程度的整合:LLMs可以成为个人数字助手。想象一下功能强大的Siri,你就会明白这个想法。LLMs可以成为虚拟助手,帮助你处理从提供餐点建议到处理通信的一切事务。
这只是LLMs在我们生活中可能发挥更大作用的一些领域。
LLMs改变和教育
LLMs正为我们打开一个充满可能性的新世界。ChatGPT、Bing Chat和Google Bard等聊天机器人的快速崛起证明了工业界对这一领域投入了大量资源。
这种资源的大量涌现只会使这些工具变得更加强大、多功能和准确。这样的工具潜在应用范围广阔,目前我们只是刚刚开始探索一个了不起的新资源而已。